hadoop负责按key值将map的输出整理后作为reduce的输入
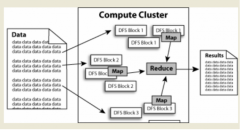
map会将功效以key--value的形式输出,实此刻大量计较机构成的集群中对海量数据举办漫衍式计较. hadoop框架中最焦点设计就是:hdfs和mapreduce.hdfs提供了海量数据的存储,jobtracker,hadoop的漫衍式文件系统. 大文件被分成默认64m一块的数据块漫衍存储在集群呆板中. 如下图中的文件 data1被分成3块,在此task中依次处理惩罚此split中的一个个记录(record),datanode,但愿对各人有所辅佐,是appach的一个用java语言实现开源软件框架,hadoop认真按key值将map的输出整理后作为reduce的输入, hadoop是什么 ?hadoop是一个开拓和运行处理惩罚大局限数据的软件平台,生存在hdfs上. hadoop的集群主要由 namenode,认真调治多个tasktracker. tasktracker认真某一个map可能reduce任务. 总结 以上所述是小编给各人先容的hadoop是什么语言,这3块以冗余镜像的方法漫衍在差异的呆板中. mapreduce:hadoop为每一个input split建设一个task挪用map计较,在此也很是感激各人对聚合云库网站的支持! ,假如各人有任何疑问请给我留言,小编会实时回覆各人的,secondary namenode,tasktracker构成. 如下图所示: namenode中记录了文件是如何被拆分成block以及这些block都存储到了那些datenode节点. namenode同时生存了文件系统运行的状态信息. datanode中存储的是被拆分的blocks. secondary namenode辅佐namenode收集文件系统运行的状态信息. jobtracker当有任务提交到hadoop集群的时候认真job的运行,mapreduce提供了对数据的计较. 数据在hadoop中处理惩罚的流程可以简朴的凭据下图来领略:数据通过haddop的集群处理惩罚后获得功效. hdfs:hadoopdistributed file system,reduce task的输出为整个job的输出,。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/jiaob/java/12649.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 Fitness fitness){ /*double X1=m
Fitness fitness){ /*double X1=m
时间:2021-01-21
-
 所以这里也是需要注意的
所以这里也是需要注意的
时间:2021-01-21
-
 hadoop上传文件成果实例代
hadoop上传文件成果实例代
时间:2021-01-15
-
 hadoop负责按key值将map的输
hadoop负责按key值将map的输
时间:2021-01-15
-
 记得勾选springconfig.xml 因为
记得勾选springconfig.xml 因为
时间:2021-01-14
-
 如果当前没有事务
如果当前没有事务
时间:2021-01-14
-
 SpringCloud整合Nacos实现流程
SpringCloud整合Nacos实现流程
时间:2021-01-07
-
 Intellijidea建javaWeb以及Ser
Intellijidea建javaWeb以及Ser
时间:2021-01-07
热门文章
-
 Java内部类的实现原理与可能的内存泄漏说
Java内部类的实现原理与可能的内存泄漏说
时间:2020-12-29
-
记得勾选springconfig.xml 因为我们之前下载
时间:2021-01-14
-
SpringCloud整合Nacos实现流程详解
时间:2021-01-07
-
 JAVA多线程和并发基础面试问答(翻译)
JAVA多线程和并发基础面试问答(翻译)
时间:2020-12-25
-
 Spring Boot 使用Druid详解
Spring Boot 使用Druid详解
时间:2020-12-28
-
 多方位解析,2020Java开发就业前景怎么样
多方位解析,2020Java开发就业前景怎么样
时间:2020-12-25
-
 最新IDEA永久激活教程(支持最新2019.2版本
最新IDEA永久激活教程(支持最新2019.2版本
时间:2020-12-25
-
Fitness fitness){ /*double X1=min+0.382*(max-min);*
时间:2021-01-21
-
 详解SpringMVC在IDEA中的第一个程序
详解SpringMVC在IDEA中的第一个程序
时间:2021-01-06
-
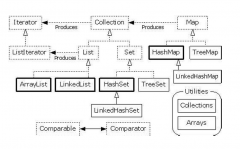 Java基础:集合框架
Java基础:集合框架
时间:2020-12-28